Хочу запустить ллама 3.1 8б, квантизация 4 или 6 бит, обязательно через видеокарту.
Конфигурация:
1070 на 8 гб
обычный рам 64 гб
процессор 7700
вин 7 64-бит

(читать дальше)
Где-то пишут, что будет работать только на гефорсах 3ххх или 4ххх, это всё чушь. Главное, чтобы помещалось в видеопамять.
Запускать решил через ллама.цпп, потому что больше ничего не знал. Работал по советам himself.
Довольно быстро выяснилось:
1. ллама.цпп не работает под вин7
2. Она требует CUDA 11.7 или 12.х, которые тоже не работают под вин7.
Запуск под вин7 -- принципиальный момент. Ставить десятку я не хочу и не буду. Скорее я на линукс перейду (хотя на ноутбуке у меня десятка, но я надеюсь исправить это недоразумение).
В общем, я решил собрать из сорцев и посмотреть, что там, почему не работает под семёрку. Сорцы берём отсюда: github.com/ggerganov/llama.cpp/releases
Итак, дальше максимально коротко (но получилось всё равно длинно):
1. Хотя везде написано, что куда 11.x не работает под семёрку, это неправда (почти неправда). Качаем и ставим (я поставил 11.8). Но 10.2 тоже качаем и ставим параллельно, потом об'ясню, зачем.
2. ллама.цпп довольно легко собирается под семёрку через w64devkit и make, только собирается она с работой через цпу (~2 токена в секунду). Это неинтересно. Проблемы при работе с w64devkit:
а) Надо поправить в мейкфайле версию винды с 0x602 на 0x601.
б) Запускать придётся с параметром -no-mmap, а то будут проблемы с длл-ками; я думаю это решаемо созданием заглушки для функции PrefetchVirtualMemory(), которая есть только в восьмёрке. Она не должна серьёзно влиять на производительность (алё, мы запускаем нейронку на цпу, тут уже без разницы).
3. Собрать через в64девкит версию с кудой невозможно, ПОТОМУ ЧТО, как выяснилось, куда сама не умеет компилировать, а требует дополнительный компилятор. И если куда под линукс может работать через гцц, то под винду поддерживается только cl.exe из вижуал студии. А в64девкит про это не знает и вызывает цл.ехе с параметрами, как для гцц. Естественно, ничего не собирается.
4. Следующая итерация: MSVS 2019. Младше не подходит, потому что через мсвс идёт сборка через CMake, и там надо, чтобы версия этого цмейка была 3.13, а в 2017 студии версия меньше. Ставим BuildTools, потому что они меньше по размеру. Вызываем ком. строку из главного меню, из раздела вижуал студии, чтобы все PATH были правильно подписаны. Пишем команды по вот этой инструкции: blog.gopenai.com/how-to-build-llama-cpp-on-wind..., а именно:
mkdir build && cd build
cmake .. -DLLAMA_CUDA=ON
cmake --build . --config Release
5. Ничего не собирается с загадочными сообщениями: "CUDA found", "No CUDA toolset found!", потому что ОКАЗЫВАЕТСЯ, сначала надо было ставить мсвс, а потому куду. Но повторная попытка установки куды показывает, что она всё равно не видит мсвс. Связать мсвс и куду можно вручную, если последовать первому совету в этом вопросе: stackoverflow.com/questions/56636714/cuda-compi..., а именно вручную распаковать установщик и перенести четыре файла из папки .\visual_studio_integration\CUDAVisualStudioIntegration\extras\visual_studio_integration\MSBuildExtensions в папку C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\MSBuild\Microsoft\VC\v160\BuildCustomizations . (взрыв мозга)

6. После сборки, чертыхаясь, открываем CMakeLists.txt и уже там меняем номер версии винды с 0x602 на 0x601. Собираем ещё раз.
7. У нас всё собралось, но по-прежнему ничего не работает, поскольку ОКАЗЫВАЕТСЯ, что ллама-цпп грузит cudart64_110.dll (расположенный в C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin), который сам собран для вин8. Поэтому хотя он и не использует специфических вин8 функций, но всё равно не запускается. Можно пробовать подкладывать ему библиотеки из вин8, но я решил поступить более радикально. Я взял аналогичный файл (cudart64_102.dll) из куды 10.2 (вы помните, мы его ставили?) и заменил с переименованием. Удивительно, но это помогло!
8. Это всё хорошо. Теперь у вас будет работать llama-cli.exe, но хочется комфорта. Хочется llama-server.exe, который будет показывать веб-морду с чатом в браузере. Разработчики ллама-сервер использовали функции, доступные только в вин8, например CreateFile2. Это не функции с настоящим новым функционалом, это старые добрые функции, которым выдали варианты с укороченным списком параметров. Придётся вручную заменить новые функции на старые. Конкретные строки можно посмотреть тут: github.com/ggerganov/llama.cpp/pull/8208/commit... . Это уже сделали до меня. Для полноты я привожу тут эти строки целиком:
hFile_ = ::CreateFile2(wpath.c_str(), GENERIC_READ, FILE_SHARE_READ, OPEN_EXISTING, NULL);
->
hFile_ = ::CreateFileW(wpath.c_str(), GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, 0, NULL);
::CreateFileMappingFromApp(hFile_, NULL, PAGE_READONLY, size_, NULL);
->
::CreateFileMappingW(hFile_, NULL, PAGE_READONLY, size.HighPart, size.LowPart, NULL);
addr_ = ::MapViewOfFileFromApp(hMapping_, FILE_MAP_READ, 0, 0);
->
addr_ = ::MapViewOfFile(hMapping_, FILE_MAP_READ, 0, 0, 0);
После этого надо опять запустить сборку. Уже последнюю.
===
Теперь сам запуск. Модель качается с hugging face. Официальные модели можно скачать только после регистрации, однако различные переработки доступны к скачиванию без регистрации. Я использовал вот этот вариант:
huggingface.co/grimjim/Llama-3.1-8B-Instruct-ab...
Сначала на 4 бита, потом на 6 бит. 8 бит не влезло. Качать надо версию, размер которой составляет от 1/2 до 3/4 размера вашей видеопамяти.
Переходим в командной строке в папку с экзешниками и пишем:
llama-server --port 8081 -c 2048 -ngl 50 -m path\to\model
-port: это порт, на котором будет висеть сервер. Если всё запустится, то веб-морда будет по адресу 127.0.0.1:8081
-c: это размер контекста. Сумма размеров сети и контекста должна быть меньше об'ёма видеопамяти. Проблема в том, что размер контекста задаётся в токенах, а токены нельзя простым образом перевести в мегабайты. Для Q6 версии один токен занимает 125 KiB. Я на своей карте смог завести с контекстом в 10000, а в 12000 уже не смог, хотя по сумме должно влезать. Пока с этим не разобрался (Алсо, при большом контексте почему-то начало зверски тормозить). По умолчанию размер контекста равен 131072, что требует 16 гигабайт видеопамяти только на него. Многовато.
-ngl: число слоёв, выгруженных на видеокарту. Ничего страшного, если тут будет больше, чем есть на самом деле. У этой сети 33 слоя.
Ну и вот, теперь можно работать:
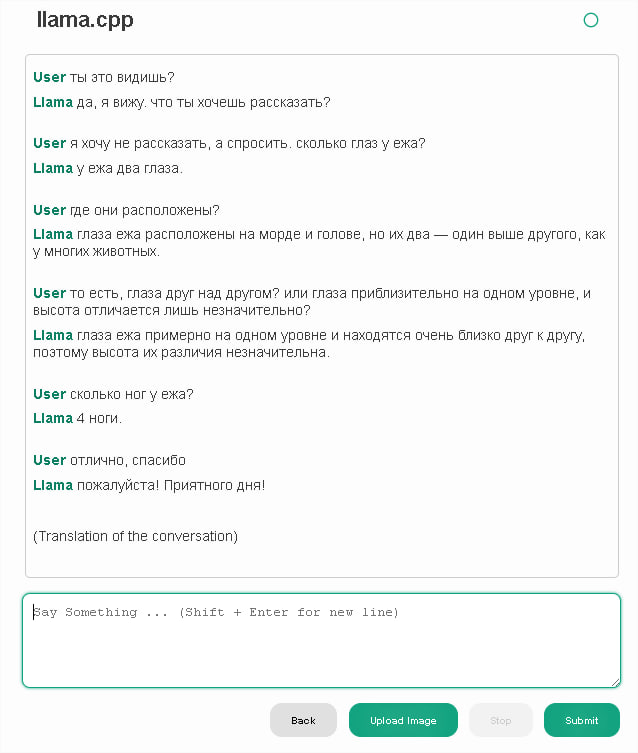
Увы, аналогичные по размеру нейронки не знают анатомию ежей.

Небольшой рол-плей.

Тут я проверяю задачу про сестёр Алисы. Результаты неутешительные, но смешные.
Примерно 20 токенов в секунду. Это в 10 раз лучше, чем на процессоре. (whisper AI показывал такую же разницу)
В следующей серии мы будем запускать под виндоуз 7 новейшие StableDiffusion и FLUX. Стоя и в гамаке -- вот наш девиз!
Конфигурация:
1070 на 8 гб
обычный рам 64 гб
процессор 7700
вин 7 64-бит
(читать дальше)
Где-то пишут, что будет работать только на гефорсах 3ххх или 4ххх, это всё чушь. Главное, чтобы помещалось в видеопамять.
Запускать решил через ллама.цпп, потому что больше ничего не знал. Работал по советам himself.
Довольно быстро выяснилось:
1. ллама.цпп не работает под вин7
2. Она требует CUDA 11.7 или 12.х, которые тоже не работают под вин7.
Запуск под вин7 -- принципиальный момент. Ставить десятку я не хочу и не буду. Скорее я на линукс перейду (хотя на ноутбуке у меня десятка, но я надеюсь исправить это недоразумение).
В общем, я решил собрать из сорцев и посмотреть, что там, почему не работает под семёрку. Сорцы берём отсюда: github.com/ggerganov/llama.cpp/releases
Итак, дальше максимально коротко (но получилось всё равно длинно):
1. Хотя везде написано, что куда 11.x не работает под семёрку, это неправда (почти неправда). Качаем и ставим (я поставил 11.8). Но 10.2 тоже качаем и ставим параллельно, потом об'ясню, зачем.
2. ллама.цпп довольно легко собирается под семёрку через w64devkit и make, только собирается она с работой через цпу (~2 токена в секунду). Это неинтересно. Проблемы при работе с w64devkit:
а) Надо поправить в мейкфайле версию винды с 0x602 на 0x601.
б) Запускать придётся с параметром -no-mmap, а то будут проблемы с длл-ками; я думаю это решаемо созданием заглушки для функции PrefetchVirtualMemory(), которая есть только в восьмёрке. Она не должна серьёзно влиять на производительность (алё, мы запускаем нейронку на цпу, тут уже без разницы).
3. Собрать через в64девкит версию с кудой невозможно, ПОТОМУ ЧТО, как выяснилось, куда сама не умеет компилировать, а требует дополнительный компилятор. И если куда под линукс может работать через гцц, то под винду поддерживается только cl.exe из вижуал студии. А в64девкит про это не знает и вызывает цл.ехе с параметрами, как для гцц. Естественно, ничего не собирается.
4. Следующая итерация: MSVS 2019. Младше не подходит, потому что через мсвс идёт сборка через CMake, и там надо, чтобы версия этого цмейка была 3.13, а в 2017 студии версия меньше. Ставим BuildTools, потому что они меньше по размеру. Вызываем ком. строку из главного меню, из раздела вижуал студии, чтобы все PATH были правильно подписаны. Пишем команды по вот этой инструкции: blog.gopenai.com/how-to-build-llama-cpp-on-wind..., а именно:
mkdir build && cd build
cmake .. -DLLAMA_CUDA=ON
cmake --build . --config Release
5. Ничего не собирается с загадочными сообщениями: "CUDA found", "No CUDA toolset found!", потому что ОКАЗЫВАЕТСЯ, сначала надо было ставить мсвс, а потому куду. Но повторная попытка установки куды показывает, что она всё равно не видит мсвс. Связать мсвс и куду можно вручную, если последовать первому совету в этом вопросе: stackoverflow.com/questions/56636714/cuda-compi..., а именно вручную распаковать установщик и перенести четыре файла из папки .\visual_studio_integration\CUDAVisualStudioIntegration\extras\visual_studio_integration\MSBuildExtensions в папку C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\MSBuild\Microsoft\VC\v160\BuildCustomizations . (взрыв мозга)
6. После сборки, чертыхаясь, открываем CMakeLists.txt и уже там меняем номер версии винды с 0x602 на 0x601. Собираем ещё раз.
7. У нас всё собралось, но по-прежнему ничего не работает, поскольку ОКАЗЫВАЕТСЯ, что ллама-цпп грузит cudart64_110.dll (расположенный в C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin), который сам собран для вин8. Поэтому хотя он и не использует специфических вин8 функций, но всё равно не запускается. Можно пробовать подкладывать ему библиотеки из вин8, но я решил поступить более радикально. Я взял аналогичный файл (cudart64_102.dll) из куды 10.2 (вы помните, мы его ставили?) и заменил с переименованием. Удивительно, но это помогло!
8. Это всё хорошо. Теперь у вас будет работать llama-cli.exe, но хочется комфорта. Хочется llama-server.exe, который будет показывать веб-морду с чатом в браузере. Разработчики ллама-сервер использовали функции, доступные только в вин8, например CreateFile2. Это не функции с настоящим новым функционалом, это старые добрые функции, которым выдали варианты с укороченным списком параметров. Придётся вручную заменить новые функции на старые. Конкретные строки можно посмотреть тут: github.com/ggerganov/llama.cpp/pull/8208/commit... . Это уже сделали до меня. Для полноты я привожу тут эти строки целиком:
hFile_ = ::CreateFile2(wpath.c_str(), GENERIC_READ, FILE_SHARE_READ, OPEN_EXISTING, NULL);
->
hFile_ = ::CreateFileW(wpath.c_str(), GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, 0, NULL);
::CreateFileMappingFromApp(hFile_, NULL, PAGE_READONLY, size_, NULL);
->
::CreateFileMappingW(hFile_, NULL, PAGE_READONLY, size.HighPart, size.LowPart, NULL);
addr_ = ::MapViewOfFileFromApp(hMapping_, FILE_MAP_READ, 0, 0);
->
addr_ = ::MapViewOfFile(hMapping_, FILE_MAP_READ, 0, 0, 0);
После этого надо опять запустить сборку. Уже последнюю.
===
Теперь сам запуск. Модель качается с hugging face. Официальные модели можно скачать только после регистрации, однако различные переработки доступны к скачиванию без регистрации. Я использовал вот этот вариант:
huggingface.co/grimjim/Llama-3.1-8B-Instruct-ab...
Сначала на 4 бита, потом на 6 бит. 8 бит не влезло. Качать надо версию, размер которой составляет от 1/2 до 3/4 размера вашей видеопамяти.
Переходим в командной строке в папку с экзешниками и пишем:
llama-server --port 8081 -c 2048 -ngl 50 -m path\to\model
-port: это порт, на котором будет висеть сервер. Если всё запустится, то веб-морда будет по адресу 127.0.0.1:8081
-c: это размер контекста. Сумма размеров сети и контекста должна быть меньше об'ёма видеопамяти. Проблема в том, что размер контекста задаётся в токенах, а токены нельзя простым образом перевести в мегабайты. Для Q6 версии один токен занимает 125 KiB. Я на своей карте смог завести с контекстом в 10000, а в 12000 уже не смог, хотя по сумме должно влезать. Пока с этим не разобрался (Алсо, при большом контексте почему-то начало зверски тормозить). По умолчанию размер контекста равен 131072, что требует 16 гигабайт видеопамяти только на него. Многовато.
-ngl: число слоёв, выгруженных на видеокарту. Ничего страшного, если тут будет больше, чем есть на самом деле. У этой сети 33 слоя.
Ну и вот, теперь можно работать:
Увы, аналогичные по размеру нейронки не знают анатомию ежей.
Небольшой рол-плей.
Тут я проверяю задачу про сестёр Алисы. Результаты неутешительные, но смешные.
Примерно 20 токенов в секунду. Это в 10 раз лучше, чем на процессоре. (whisper AI показывал такую же разницу)
В следующей серии мы будем запускать под виндоуз 7 новейшие StableDiffusion и FLUX. Стоя и в гамаке -- вот наш девиз!
@темы: Борьба с техникой, Статьи